The Challenge: Round two with an old nemesis
Recruiting is broken. Finding the right candidates is like searching for needles in a haystack, and when you do find them, your generic LinkedIn message gets lost in their inbox with 50 others.
For Synapse’s AI hackathon, the challenge was to “Build a LinkedIn Sourcing Agent that finds profiles, scores candidates using AI, and generates personalized outreach messages.”
Two years ago, I tried building something similar: a LinkedIn scraper combined with a job recommendation engine. I was going to scrape LinkedIn jobs, match them to user resumes, and use that to reduce information overload in job searching. LinkedIn’s anti-scraping measures crushed that dream within days.
Back then, I had less technical knowledge but even with perfect execution, it wouldn’t have worked. LinkedIn’s defenses are just too aggressive. I pivoted to scraping job postings from Indeed and YCombinator instead.
That experience taught me LinkedIn scraping is essentially impossible without using paid solutions. So when this hackathon challenge came up, I knew what not to do.
Table of Contents
Open Table of Contents
What I Built
Instead of another keyword-matching tool, I built something that tries to think like a recruiter:
Job Description → Smart Search → Profile Scraping → AI Scoring → Personalized Messages
The core components:
- Multi-source discovery: LinkedIn + GitHub profile combination
- 6-factor scoring algorithm: Because fit isn’t just about keywords
- AI-powered outreach: Llama via Groq for personalized messaging
- Async processing: Handle multiple jobs without blocking
You can check out the full code here.
The Architecture
I used FastAPI for the backend with async processing throughout. The data flow looks like this:
- Search Query Generation: Transform job descriptions into effective search queries
- Profile Discovery: SerpAPI to find profiles - LinkedIn and Github URLs
- Data Fetch: RapidAPI’s LinkedIn service (because scraping LinkedIn directly is a nightmare), HTTP calls for Github
- Data Extraction: Custom logic (using BeautifulSoup for Github)
- Intelligent Scoring: 6-factor algorithm with confidence levels
- Message Generation: Llama-powered personalized outreach
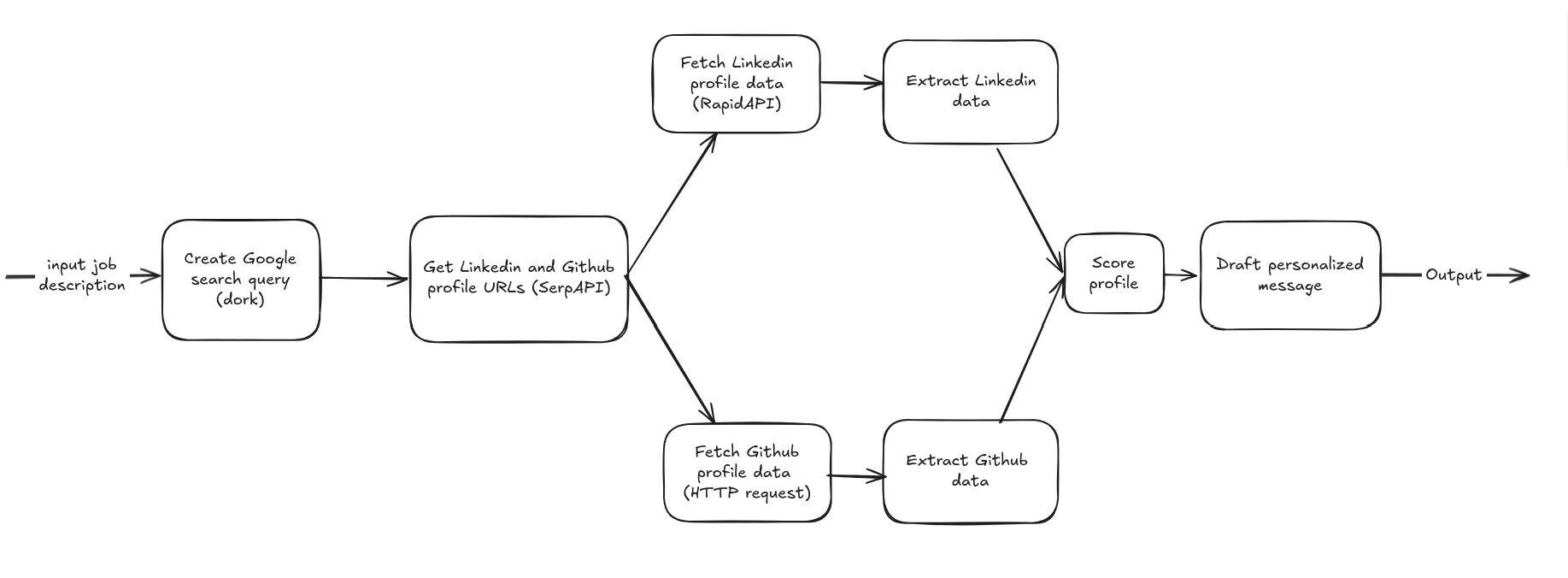 Data flow diagram
Data flow diagram
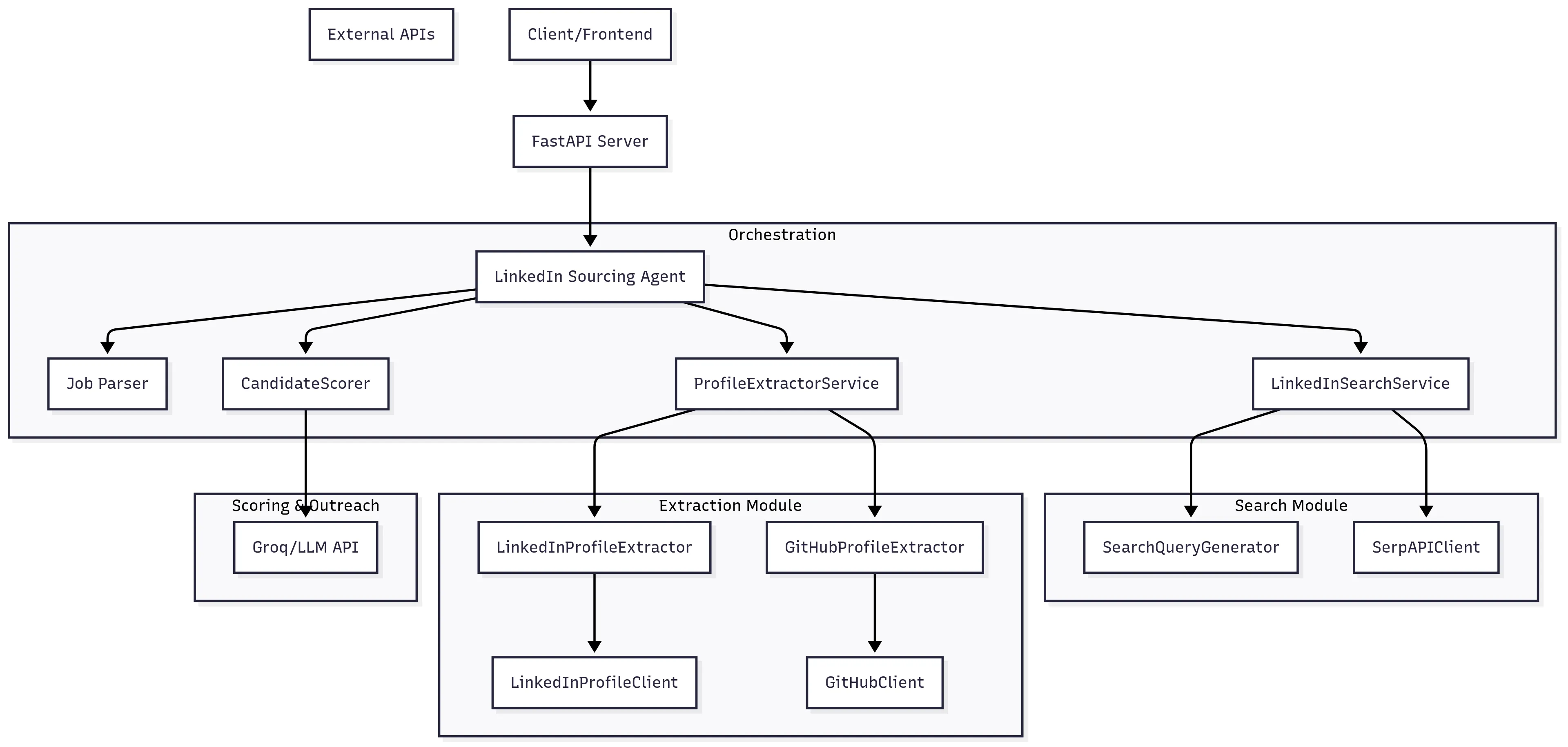 App architecture
App architecture
The Scoring Algorithm
| Factor | Weight | What It Measures |
|---|---|---|
| Education | 20% | Elite schools get higher scores |
| Career Trajectory | 20% | Clear progression vs. lateral moves |
| Company Relevance | 15% | Relevant industry experience |
| Skill Match | 25% | How well skills align with job requirements |
| Location | 10% | Geographic fit for the role |
| Tenure | 10% | Stability vs. job hopping patterns |
Since it’s using LLMs, it understands context. A engineer who moved from startup → Google → senior role gets a higher trajectory score than someone who stayed at the same level for years.
Smart Outreach Generation
Generic LinkedIn messages get ignored. My solution uses Llama (via Groq) to create personalized messages that:
- Reference specific experience and achievements
- Connect candidate background to job requirements
- Feel personal, not templated
- Include clear next steps
Example output: “Hi John, I noticed your work at OpenAI on transformer architectures and your ICML 2023 paper on attention mechanisms. Your blend of research and production ML experience is exactly what Windsurf needs for their ML Research Engineer role…”
Sample Results
Testing with the Windsurf ML Research Engineer role:
{
"name": "John Doe",
"fit_score": 8.7,
"confidence": 0.91,
"score_breakdown": {
"education": 9.2, // Stanford PhD in ML
"trajectory": 8.5, // Research → Engineering → Lead
"company": 9.0, // Google, OpenAI experience
"skills": 9.1, // Perfect LLM/transformer match
"location": 10.0, // Mountain View based
"tenure": 7.8 // Healthy 2-3 year progression
},
"outreach_message": "Hi John, I came across your transformer optimization work at Google Research, particularly your ICML paper on efficient attention mechanisms. Your move from research to production ML at OpenAI shows the exact blend we need at Windsurf..."
}Why this works for this JD:
- Specific achievements (ICML paper)
- Career progression understanding
- Clear connection to role requirements
Key Technical Decisions
Why These Choices Mattered
Llama via Groq instead of OpenAI: Faster, cheaper, and surprisingly good at personalized messaging
RapidAPI for LinkedIn data: More reliable than web scraping, cleaner data extraction
Async processing with FastAPI: Can handle multiple jobs in parallel without blocking
MongoDB for storage: Perfect for flexible candidate profiles and easy scaling
Smart caching: Avoids re-fetching the same profiles, reduces overhead, cost
What I Learned
1. Focus on the Algorithm, Not the Data Collection
Anyone can scrape LinkedIn (using paid APIs to fetch data). The value is in smart scoring that understands candidate quality beyond keywords, to automate the manual tasks and reduce information that needs to be processed.
2. Personalization Actually Works
Generic outreach gets low response rates. AI-generated personalized messages referencing specific achievements can convert a lot of leads.
As a fallback, we always have template messages.
3. Production Thinking From Day 1
Built with FastAPI, async processing, proper error handling, and caching. This is designed to scale easily.
4. Multi-Source Data is Key
Combining LinkedIn + GitHub profiles gives much richer candidate insights than either alone.
Scaling Strategy
For production use (100s of jobs daily):
- Async Processing: Already built with asyncio for parallel job handling. Can explore multiprocessing as well
- Queue System: Redis/Celery integration template implemented, integration remains
- Database: MongoDB for caching profiles and storing results
- Rate Limiting: Smart backoff with API key rotation
- Observability: Comprehensive logging for performance tracking (add complex later)
- Comprehensive Testing: Including load testing, e2e and more
The Real Challenges (And Why They Matter)
- LinkedIn’s War Against Scraping (Round Two) LinkedIn really, really doesn’t want you scraping their data. Having learned this lesson the hard way two years ago, I didn’t even attempt direct scraping this time. My previous attempt involved rotating user agents, proxy pools, CAPTCHA solving - all of it failed within days.
This time I went straight to RapidAPI’s LinkedIn service. More expensive per request ($0.01 per profile), but infinitely more reliable than fighting LinkedIn’s ever-evolving bot detection. My 2022 self would have spent weeks trying to outsmart their defenses. My 2024 self just paid for the API.
Lesson learned: Sometimes the expensive solution is actually the cheap one when you factor in development time.
- LLM Consistency is a Myth
Groq’s Llama model was supposed to return structured JSON for scoring. In practice? It worked maybe 70% of the time. The other 30% I’d get beautifully written prose instead of the JSON structure I needed.
What I learned: Always have fallback parsing. I ended up writing regex patterns to extract scores from malformed responses, and implementing retry logic with different prompts.
- GitHub Profile Matching Gone Wrong
Searching for Github profiles is not straightforward, I would get Company profiles suggested instead of people.
Combining LinkedIn and GitHub data seemed straightforward - match by name and see if their GitHub activity aligns with their LinkedIn experience. Reality check: turns out “John Smith” working at “Google” could match with 47 different GitHub profiles.
Current state: I built the GitHub integration but disabled it for the final demo. Sometimes the feature that sounds coolest causes the most headaches.
- The MongoDB Integration That Never Happened
I planned to use MongoDB with Motor for async operations.
What actually happened: spending hours debugging data validation mismatches took up a lot of time. For the hackathon timeline, I switched to simple JSON file caching.
Lesson: Sometimes the “better” technical choice isn’t worth the time cost, especially under deadline pressure.
- Data Validation
The biggest and stupidest issue that plagued me. A major chunk of my time building was debugging and fixing data validation issues, so I started doing a TDD style thing midway, made my logger verbose to capture a ton of context.
What actually worked well
Caching
I implemented a simple profile caching that actually saves time and API costs. Before making any external calls, the system checks if we’ve seen this LinkedIn URL before. For a hackathon scale, simple file-based caching works fine. For production, I’d use Redis with proper TTL settings.
Async Processing
FastAPI with asyncio lets me process multiple candidates simultaneously. Instead of waiting 30 seconds for 10 profiles sequentially, I can get them all in 5-6 seconds.
I could have used FastAPI’s BackgroundTasks, but it wouldn’t have made a lot of difference. It would be a lot more sensible to go to a task queue based setup for scaling (using Redis + Celery).
LLM based scoring
Rather than just keyword matching, LLMs understands context. An engineer who went from startup → Google → senior role gets higher trajectory scores than someone who’s been at the same level for years. The LLM can recognize patterns that regex never could.
Scaling
The current system handles maybe 20-30 profiles before throttling and API rate limits kick in. For production scale (hundreds of concurrent jobs), here’s what needs to change:
Code Quality & Architecture
The current codebase is a mess of random object creation everywhere. I’m instantiating API clients, scrapers, and scoring services scattered throughout the code. This makes testing painful and concurrency unpredictable.
Dependency injection would clean this up significantly. Instead of creating LinkedInScraper() objects everywhere, I’d inject them as dependencies. For FastAPI, this means using dependency providers that create singleton instances for thread-safe operations.
# Current messy approach
async def score_candidates(candidates):
scraper = LinkedInScraper() # New instance every time
scorer = FitScorer() # Another new instance
# ... rest of logic
# Better approach with DI
async def score_candidates(
candidates,
scraper: LinkedInScraper = Depends(get_scraper),
scorer: FitScorer = Depends(get_scorer)
):
# Clean, testable, predictableFor concurrency, dependency injection actually helps. You can inject thread-safe, connection-pooled clients rather than creating new HTTP sessions for every request. This reduces overhead and prevents connection exhaustion.
Combining DI with connection pooling is another great idea.
API key rotation
Though the code is setup, it’s not being used. Ideally would prefer to use a bunch of generators to do this, would help when rate limits for one API kick in.
Real Production Scaling
For hundreds of concurrent jobs, the architecture needs fundamental changes:
- Multi-Query Strategy Instead of a single search query, I’d implement tiered searching:
Strict query: Perfect keyword matches, paginate deeply (until you don’t get results) Medium query: Broader terms, fewer pages Loose query: Industry + location only, limited results
This builds a large candidate pool while prioritizing the most relevant profiles.
- Smart Pre-filtering Before hitting expensive LLMs:
Deduplication: Bloom filters for URL dedup at scale Basic filtering: Years of experience, location, title keywords Batch scoring: Group similar profiles for bulk processing
- Queue Architecture (Async Task Queue Pattern) Job Queue → Search Workers → Filter Workers → LLM Workers → Results
Each stage handles its bottlenecks independently. Search workers can run fast and cheap, while LLM workers are expensive but fewer in number.
- Resource Management
API key pools: Rotate keys across workers to handle rate limits Connection pooling: Shared HTTP clients across async workers Circuit breakers: Fail fast when external services are down
Future Roadmap
Short Term (1-2 months)
- Complete MongoDB async integration with Motor
- Dockerization for consistency across environments
- Enhanced deduplication using bloom filters
- A/B testing framework for prompt optimization
Medium Term (3-6 months)
- Multi-platform integration (Twitter, personal websites)
- Advanced ML models for candidate scoring
- Real-time job market insights
- Integration with ATS systems
Long Term (6+ months)
- Predictive analytics for hiring success
- Automated interview scheduling
- Bias detection and mitigation
- Custom model training for specific companies
Try It Yourself
GitHub Repository: score_profiles
API Documentation: Available at /docs when running locally
I tried using uv, but there were some issues on my laptop recently - so I switched to pip
# Quick start
git clone https://github.com/pranshu-raj-211/score_profiles.git
cd score_profiles
pip install -r requirements.txt
cp .env.example .env # Add your API keys
python app/main.pyAPI Usage:
curl -X POST "http://localhost:8000/jobs" \
-H "Content-Type: application/json" \
-d '{"search_query": "ML Engineer at AI startup", "max_candidates": 10}'