TL;DR:
I scaled a real-time leaderboard in Go to 28K concurrent SSE connections, but discovered that my broadcast pattern was fundamentally broken.
Fixing it taught me lessons about concurrency, backpressure, deduplication, fan-out, and observability that apply to any real-time system design.
Optimizations at a glance
- Removed per-connection Redis polling in favor of centralized poller
- Deduplication with hashing
- Broadcast using the Fan-out pattern
- Backpressure handling (clear buffer, latest update only)
- Observability with Prometheus + Grafana
Last month, I built a real-time leaderboard system in Go that could handle 28,232 concurrent SSE connections - pretty impressive for a Python developer’s first Go project.
Then I ran a test with actual score updates and watched all of my messages disappear into the void.
Here’s how I learned about Go’s concurrency model the hard way, and why understanding channels, goroutines, mutexes deeply can make the difference between a system that works in testing and one that works in production.
Some of the concepts here might be a little difficult to understand, I’m working on a second blog to explain what those are, how I’m using them and how all of those connect, their tradeoffs.
Table of contents
Open Table of contents
The goal
I wanted to build a real-time, read-mostly(write privilege to certain nodes) leaderboard that could push the same top-K view to a lot of clients over SSE.
Targets (going in):
- Handle 10k+ concurrent SSE connections on one machine.
- Every connected client gets every broadcast.
- Built-in observability as a sanity check (visibility).
Outcome (spoiler): I hit 28,232 concurrent connections, then discovered my “broadcast” only delivered to one consumer. The post walks through how I found that flaw and fixed it (correct fan-out, dedup, decoupling, backpressure).
The system
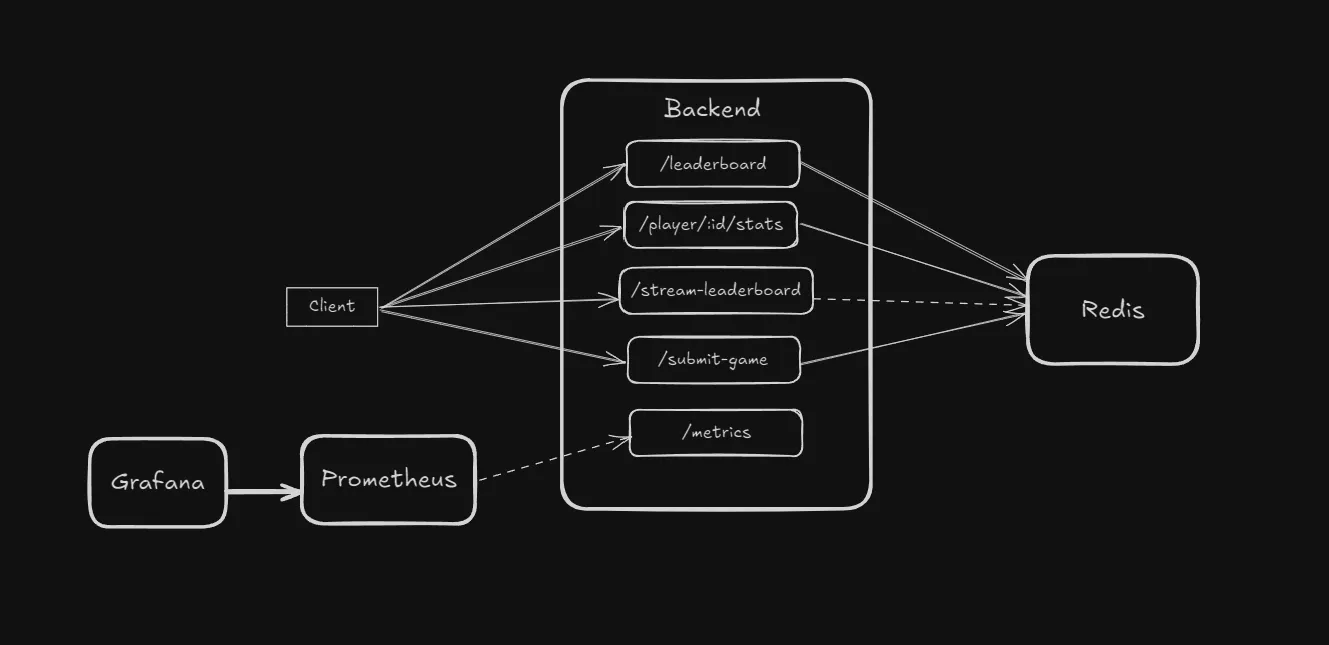
Architecture
The system is laid out into the write and read path.
Write path (Game server -> Redis)
Game servers submit game results to an endpoint, which updates the Redis sorted set (source of truth).
Read path (Redis -> clients)
A single goroutine polls Redis, detects changes, which is broadcasted (latest top-K players) to per-client buffered channels that feed SSE connections.
Other read access patterns exist, but not the topic of discussion in this post.
What this design focuses on
- The same update goes to all connected clients(correctness)
- Latest-only semantics are fine (skip intermediates under load - latest state matters, not the intermediates)
- Slow consumers don’t stall the producer (backpressure)
What this design is not concerned with
- Intermediate updates when clients reconnect. Heavy emphasis on latest state view
Given the use case, access patterns and scaling concerns, I decided to opt for a SSE based (over websocket, polling) message sending for real time leaderboard updates.
I started implementing the main SSE handling code, which I did progressively in stages, improving and learning along the way.
Legend for future diagrams
Per connection Redis polling
In this version, the SSE handler function itself contains the Redis read call, a JSON marshaling sequence.
Implemented
- Simple handler code
- Redis reads (polling every 2 seconds)
- Basic active connection metrics
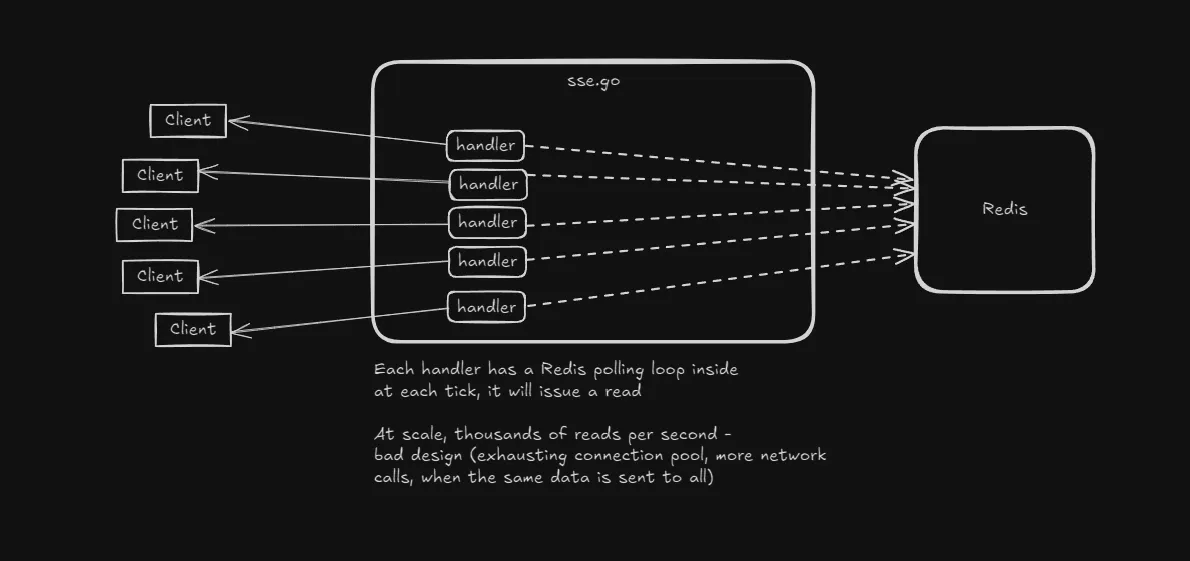
Initial implementation - note that each connection polls Redis
Click to view code
package backend
import (
"encoding/json"
"fmt"
"leaderboard/src/metrics"
"leaderboard/src/redisclient"
"time"
"github.com/gin-gonic/gin"
)
func StreamLeaderboard(c *gin.Context) {
c.Writer.Header().Set("Content-Type", "text/event-stream")
c.Writer.Header().Set("Cache-Control", "no-cache")
c.Writer.Header().Set("Connection", "keep-alive")
c.Writer.Flush()
metrics.ActiveSSEConnections.Inc()
ticker := time.NewTicker(2 * time.Second)
defer ticker.Stop()
for {
select {
case <-ticker.C:
results, err := redisclient.GetTopNPlayers(c, "leaderboard", 10)
if err != nil {
continue
}
data, _ := json.Marshal(results)
fmt.Fprintf(c.Writer, "data: %s\n\n", data)
c.Writer.Flush()
case <-c.Request.Context().Done():
return
}
}
}Why it’s flawed
- Redis reads coupled with the handler function - each SSE connection will have it’s own read call every 2 seconds. That’s immensely wasteful (considering the same data needs to go out). Higher queries per second to Redis soon becomes an issue that could turn into a scaling bottleneck.
- No deduplication - every single read gets converted to a data object to be sent over the network.
- Just returning when the connection is closed - connection closing needs to be done properly.
- Unbuffered channels - may block.
- JSON encoding on each tick.
- Active connections never decremented.
- Improper error handling.
- At scale, Redis connection pool will be exhausted.
Deduplication to reduce waste
Contains a basic deduplication measure - compare two json objects, object by object. This reduces the data sent, helpful to reduce network usage.
There’s also the addition of other metrics to help understand how things are working, what failures are occuring in the app.
Config variables are used more frequently in this update, reducing the number of hardcoded values needed. There’s still a few places where they are used, which may need to be modified later.
What improved
- Deduplication by comparing JSON objects
- Replace harcoded values by configs
- Improved Prometheus metrics
Click to view code
import (
"encoding/json"
"fmt"
+ "leaderboard/src/config"
"leaderboard/src/metrics"
"leaderboard/src/redisclient"
"time"
)
func StreamLeaderboard(c *gin.Context) {
+ metrics.ConcurrentClients.Inc()
+ defer metrics.ConcurrentClients.Dec()
+
c.Writer.Header().Set("Content-Type", "text/event-stream")
c.Writer.Header().Set("Cache-Control", "no-cache")
c.Writer.Header().Set("Connection", "keep-alive")
c.Writer.Flush()
metrics.ActiveSSEConnections.Inc()
+ defer metrics.ActiveSSEConnections.Dec()
- ticker := time.NewTicker(2 * time.Second)
+ ticker := time.NewTicker(5 * time.Second)
defer ticker.Stop()
+ var lastData []byte
+
for {
select {
case <-ticker.C:
- results, err := redisclient.GetTopNPlayers(c, "leaderboard", 10)
+ results, err := redisclient.GetTopNPlayers(c, "leaderboard", int64(config.AppConfig.Leaderboard.TopPlayersLimit))
+ if err != nil { metrics.RedisOperationErrors.WithLabelValues("get_top_players").Inc()
+ }
+ jsonStart :=time.Now()
+ data, err := json.Marshal(results)
+ metrics.JSONMarshalDuration.Observe(time.Since(jsonStart).Seconds())
+
if err != nil {
- continue
+ metrics.JSONErrors.WithLabelValues("marshal").Inc()
+ return
+ }
+ if !jsonEqual(data, lastData) {
+ fmt.Fprintf(c.Writer, "data: %s\n\n", data)
+ c.Writer.Flush()
+ metrics.SSEMessagesSent.Inc()
+ lastData = data
}
-
- data, _ := json.Marshal(results)
- fmt.Fprintf(c.Writer, "data: %s\n\n", data)
- c.Writer.Flush()
case <-c.Request.Context().Done():
+ metrics.DroppedSSEConnections.Inc()
return
}
}
+}
+
+func jsonEqual(a, b []byte) bool {
+ return string(a) == string(b)
}Why it’s flawed
- JSON object comparison is expensive (in case of large blobs, which may be encountered here).
- Marshaling still happens on each read, and each read is still coupled, which means high QPS on Redis.
Decoupling Redis reads
Instead of having each client hammering Redis, I implemented a broadcast pattern using goroutines and channels (single producer, multiple consumers).
What improved
- Separate goroutine for Redis polling
- Deduplication using hashing (SHA256)
- JSON marshaling done only when data is changed
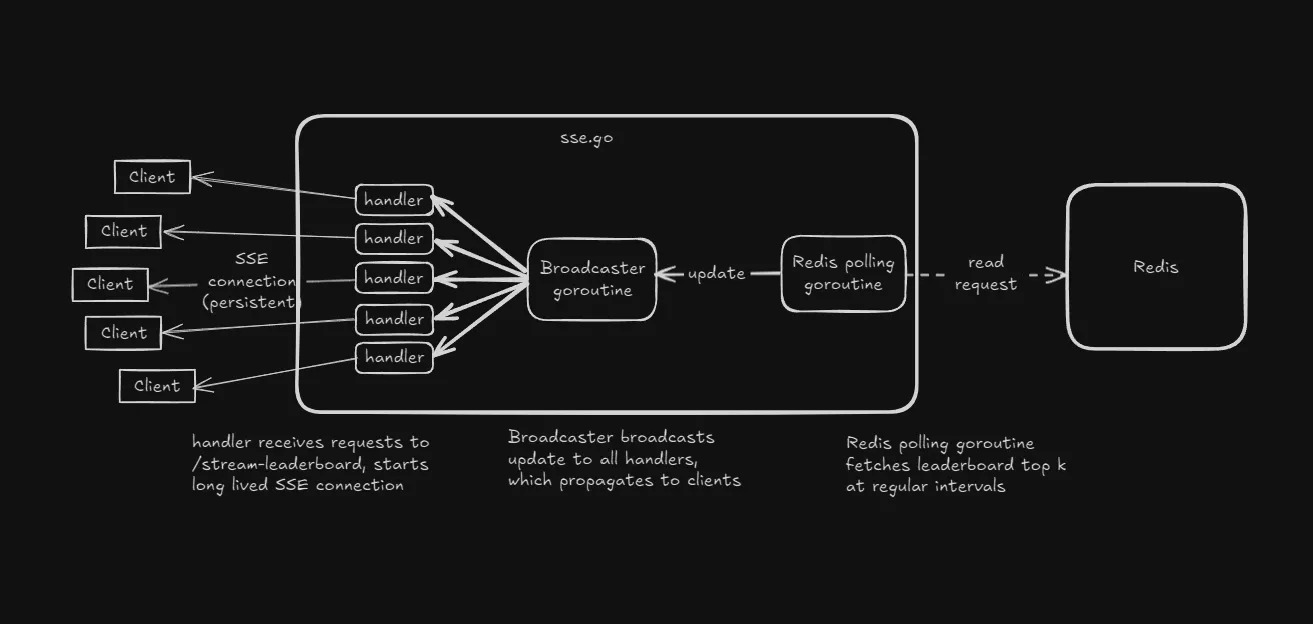
How it should have worked
Click to view code
package backend
import (
+ "context"
+ "crypto/sha256"
"encoding/json"
"fmt"
"leaderboard/src/config"
"leaderboard/src/metrics"
"leaderboard/src/redisclient"
+ "sync"
"time"
"github.com/gin-gonic/gin"
)
+type LeaderboardUpdate struct {
+ Data []byte
+ Hash [32]byte
+}
+
+type LeaderboardBroadcaster struct {
+ // channel for all SSE conns to listen to get lb updates
+ broadcastChan chan LeaderboardUpdate
+
+ ctx context.Context
+ cancel context.CancelFunc
+ wg sync.WaitGroup
+}
+
+func CreateLeaderboardBroadcaster() *LeaderboardBroadcaster {
+ ctx, cancel := context.WithCancel(context.Background())
+
+ lb := &LeaderboardBroadcaster{
+ // make the channel buffered - clients may be slow, messages can pile up
+ broadcastChan: make(chan LeaderboardUpdate, config.AppConfig.Server.BroadcastBufferSize),
+ ctx: ctx,
+ cancel: cancel,
+ }
+
+ lb.wg.Add(1)
+ go lb.detectLeaderboardChanges()
+ return lb
+}
+
+func (lb *LeaderboardBroadcaster) StopBroadcast() {
+ lb.cancel()
+ lb.wg.Wait()
+ close(lb.broadcastChan)
+}
+
+func (lb *LeaderboardBroadcaster) GetBroadcastChannel() <-chan LeaderboardUpdate {
+ return lb.broadcastChan
+}
+
+// package level var
+var broadcaster *LeaderboardBroadcaster
+
+func SetBroadcaster(b *LeaderboardBroadcaster) {
+ broadcaster = b
+}
+
+func (lb *LeaderboardBroadcaster) detectLeaderboardChanges() {
+ defer lb.wg.Done()
+
+ // TODO: check this time conversion
+ ticker := time.NewTicker(time.Duration(config.AppConfig.Server.PollingIntervalSeconds) * time.Second)
+ defer ticker.Stop()
+
+ var lastHash [32]byte
+
+ for {
+ select {
+ case <-ticker.C:
+ results, err := redisclient.GetTopNPlayers(lb.ctx, "leaderboard", int64(config.AppConfig.Leaderboard.TopPlayersLimit))
+ if err != nil {
+ metrics.RedisOperationErrors.WithLabelValues("get_top_players").Inc()
+ config.Error("Failed to fetch leaderboard from Redis.", map[string]any{"Error": err, "source": "/stream-leaderboard"})
+ continue
+ }
+
+ resultString := fmt.Sprintf("%+v", results)
+ currentHash := sha256.Sum256([]byte(resultString))
+
+ if currentHash != lastHash {
+ lastHash = currentHash
+
+ jsonStart := time.Now()
+ jsonData, err := json.Marshal(results)
+ if err != nil {
+ config.Error("JSON marshaling error",
+ map[string]any{"Error": err, "source": "/stream-leaderboard", "results": results})
+ metrics.JSONErrors.WithLabelValues("marshal").Inc()
+ continue
+ }
+ metrics.JSONMarshalDuration.Observe(time.Since(jsonStart).Seconds())
+
+ update := LeaderboardUpdate{
+ Data: jsonData,
+ Hash: currentHash,
+ }
+
+ // non blocking send
+ select {
+ case lb.broadcastChan <- update:
+ default:
+ }
+ }
+ case <-lb.ctx.Done():
+ return
+ }
+ }
+}
+
func StreamLeaderboard(c *gin.Context) {
metrics.ConcurrentClients.Inc()
defer metrics.ConcurrentClients.Dec()
c.Writer.Flush()
metrics.ActiveSSEConnections.Inc()
+ config.Info("New SSE conn", map[string]any{"Num active clients": metrics.ActiveSSEConnections})
defer metrics.ActiveSSEConnections.Dec()
- ticker := time.NewTicker(5 * time.Second)
- defer ticker.Stop()
-
- var lastData []byte
+ broadcastChan := broadcaster.GetBroadcastChannel()
for {
select {
- case <-ticker.C:
- results, err := redisclient.GetTopNPlayers(c, "leaderboard", int64(config.AppConfig.Leaderboard.TopPlayersLimit))
- if err != nil {
- metrics.RedisOperationErrors.WithLabelValues("get_top_players").Inc()
- }
- jsonStart := time.Now()
- data, err := json.Marshal(results)
- metrics.JSONMarshalDuration.Observe(time.Since(jsonStart).Seconds())
-
- if err != nil {
- metrics.JSONErrors.WithLabelValues("marshal").Inc()
+ case update, ok := <-broadcastChan:
+ if !ok {
+ // channel closed
return
}
- if !jsonEqual(data, lastData) {
- fmt.Fprintf(c.Writer, "data: %s\n\n", data)
- c.Writer.Flush()
- metrics.SSEMessagesSent.Inc()
- lastData = data
- }
+ fmt.Fprintf(c.Writer, "data: %s\n\n", update.Data)
+ c.Writer.Flush()
+ metrics.SSEMessagesSent.Inc()
case <-c.Request.Context().Done():
metrics.DroppedSSEConnections.Inc()
+ config.Info("Closed SSE conn", map[string]any{"open": metrics.ActiveSSEConnections})
return
}
}
}
-
-func jsonEqual(a, b []byte) bool {
- return string(a) == string(b)
-}Benchmarking this with a Go script that opens persistent SSE connections (based off of Eran Yanay’s Gophercon talk) got me 28,232 concurrent connections per second.
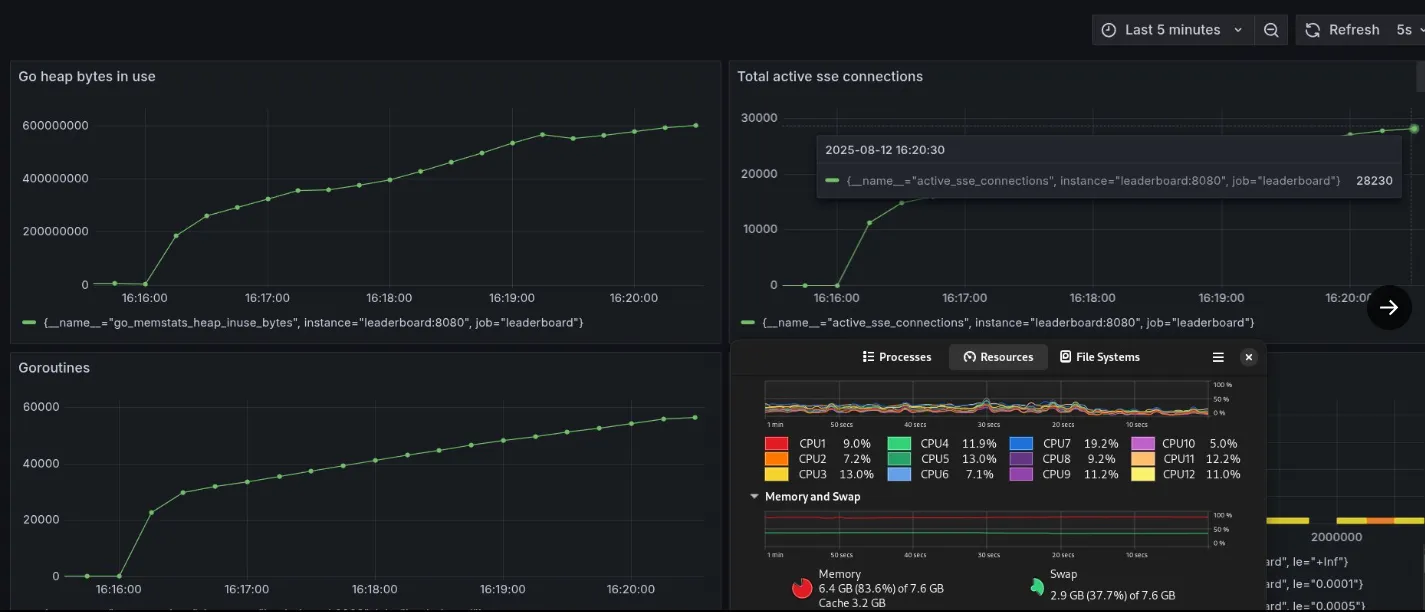
Scaled to 28,232 SSE connections after decoupling
I was pretty happy with these results, especially since the connections maxed out due to hitting the upper limit of outbound ports on Linux, not due to memory or CPU bottlenecks.
Then I realized I had a major bug which I forgot to test for.
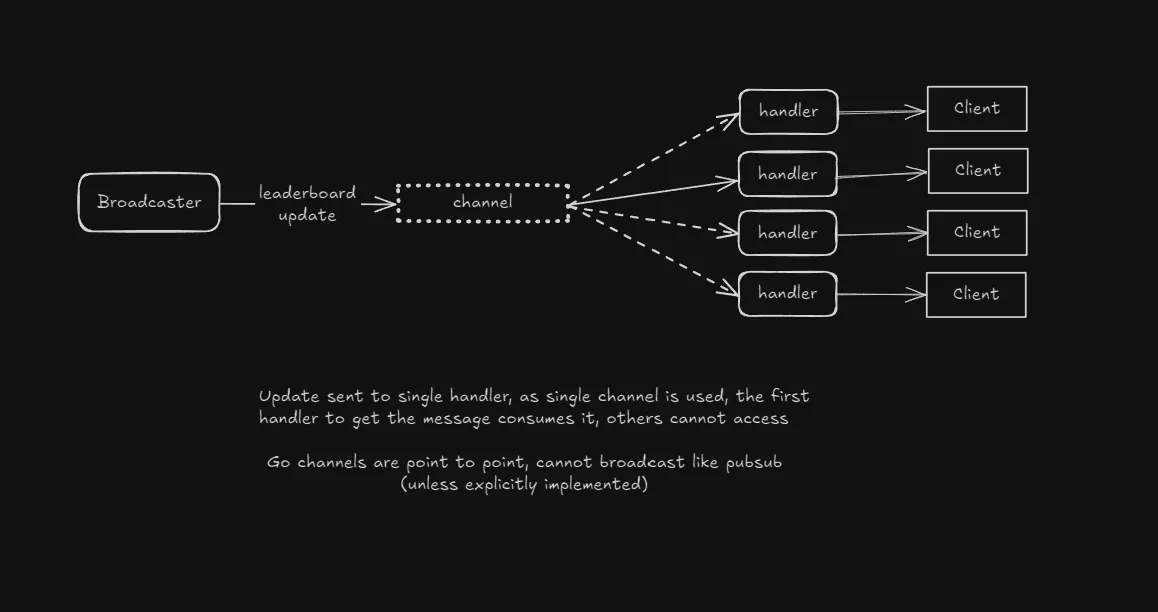
The error in my broadcasting implementation
Dashed arrows here show that all connections but one do not get a message.
Why it’s flawed
- Fan out implementation is incorrect - One message can be consumed by only a single consumer (goroutine) in a channel. This effectively means - any event added to the channel is consumed by a single goroutine, others never get the message.
- Error handling gaps.
- Initial message is not sent (messages sent only when the ticker event occurs and there is an update). We should have the client receive some leaderboard message on connect, even if it’s somewhat stale.
Fixing Fan Out
The previous version had a single channel for all broadcast messages to be sent, which would effectively be received by a single goroutine (client). This defeats the purpose of my app, for which I need every single client to receive the same message.
What improved
- One buffered channel per client, stored in a map
- Mutex applied whenever map is modified, preventing race conditions
- Leaderboard change leads to broadcasting message to all channels
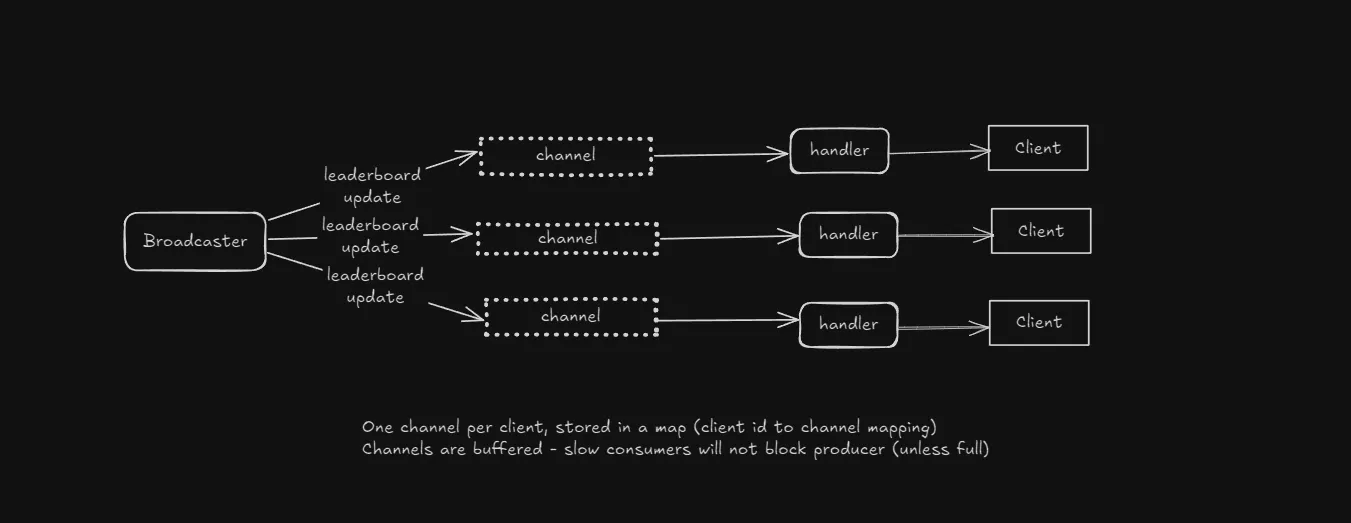
Correct fan out (broadcast) implementation
Alternative implementations might use Pubsub with popular providers, but it’s probably overkill for this use case.
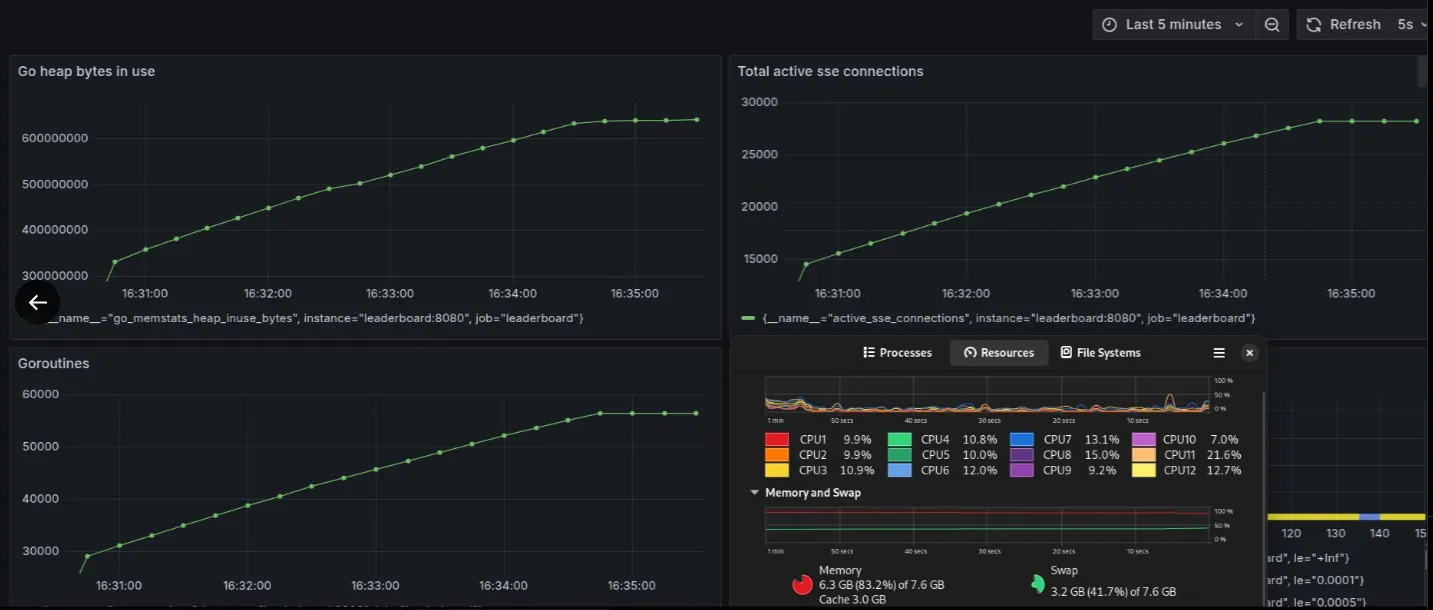
28232 connections with fixed fan out code
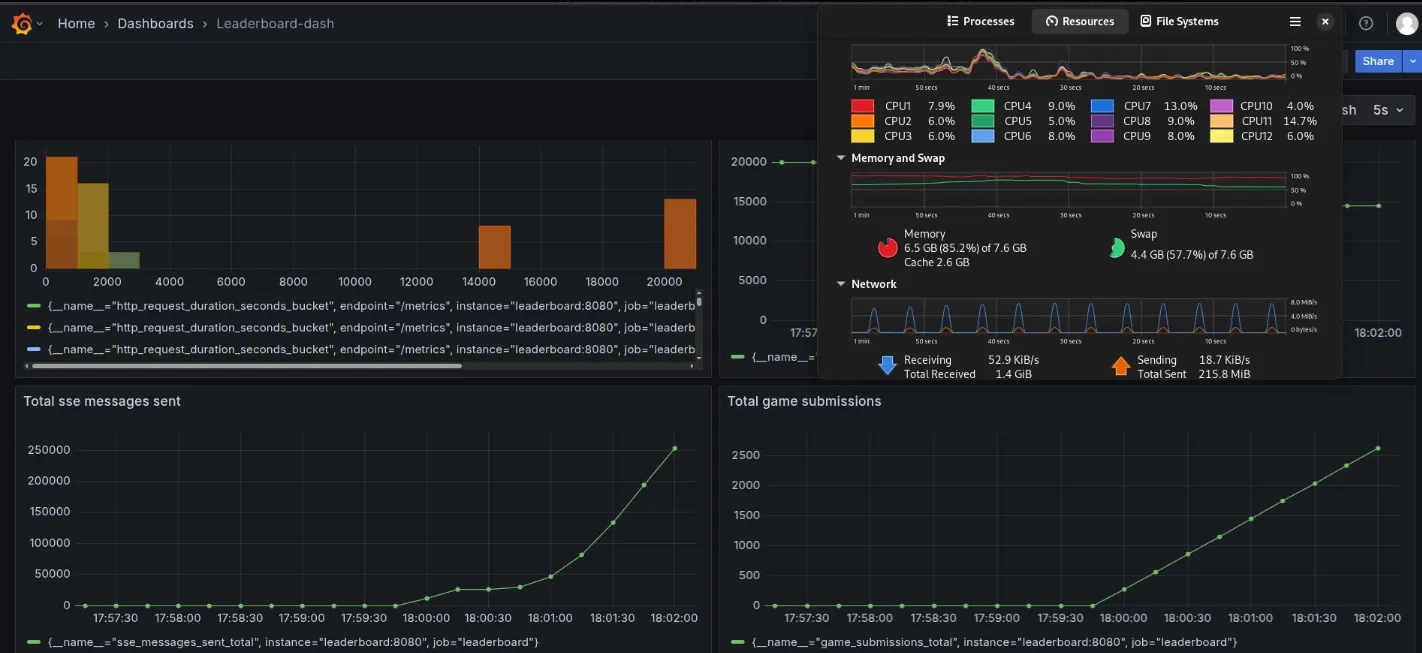
Game submissions are being received by the SSE clients - fan out works
Click to view code
-type LeaderboardBroadcaster struct {
- // channel for all SSE conns to listen to get lb updates
- broadcastChan chan LeaderboardUpdate
+type Client struct {
+ ID int64
+ channel chan LeaderboardUpdate
+ ctx context.Context
+ cancel context.CancelFunc
+}
- ctx context.Context
- cancel context.CancelFunc
- wg sync.WaitGroup
+type LeaderboardBroadcaster struct {
+ clients map[int64]*Client
+ clientsMutex sync.RWMutex
+ ctx context.Context
+ cancel context.CancelFunc
+ wg sync.WaitGroup
+ clientCounter int64
}
func CreateLeaderboardBroadcaster() *LeaderboardBroadcaster {
lb := &LeaderboardBroadcaster{
// make the channel buffered - clients may be slow, messages can pile up
- broadcastChan: make(chan LeaderboardUpdate, config.AppConfig.Server.BroadcastBufferSize),
- ctx: ctx,
- cancel: cancel,
+ clients: make(map[int64]*Client),
+ ctx: ctx,
+ cancel: cancel,
}
lb.wg.Add(1)
return lb
}
-func (lb *LeaderboardBroadcaster) GetBroadcastChannel() <-chan LeaderboardUpdate {
- return lb.broadcastChan
+// Create new channel for client, add to map
+func (lb *LeaderboardBroadcaster) AddClient() (*Client, <-chan LeaderboardUpdate) {
+ lb.clientsMutex.Lock()
+ lb.clientCounter++
+ ctx, cancel := context.WithCancel(lb.ctx)
+
+ client := &Client{
+ ID: lb.clientCounter,
+ ctx: ctx,
+ cancel: cancel,
+ channel: make(chan LeaderboardUpdate, config.AppConfig.Server.BroadcastBufferSize),
+ }
+ lb.clients[lb.clientCounter] = client
+ lb.clientsMutex.Unlock()
+
+ return client, client.channel
+}
+
+// remove specific client channel - closed connection
+func (lb *LeaderboardBroadcaster) RemoveClient(client *Client) {
+ lb.clientsMutex.Lock()
+ defer lb.clientsMutex.Unlock()
+
+ if _, exists := lb.clients[client.ID]; exists {
+ delete(lb.clients, client.ID)
+ client.cancel()
+ close(client.channel)
+ }
+}
+
+// broadcastToAllClients sends an update to all connected clients
+func (lb *LeaderboardBroadcaster) broadcastToAllClients(update LeaderboardUpdate) {
+ lb.clientsMutex.RLock()
+
+ var clientsToRemove []*Client
+
+ // what to do in case Client channel is full, skip this client (to be changed later - add channel clearing mechanism + alerting)
+ for _, client := range lb.clients {
+ select {
+ case client.channel <- update:
+ // sent
+ case <-client.ctx.Done():
+ // clean
+ clientsToRemove = append(clientsToRemove, client)
+ default:
+ metrics.FilledSSEChannels.Inc()
+ }
+ }
+ lb.clientsMutex.RUnlock()
+
+ if len(clientsToRemove) > 0 {
+ lb.clientsMutex.Lock()
+ for _, client := range clientsToRemove {
+ if _, exists := lb.clients[client.ID]; exists {
+ delete(lb.clients, client.ID)
+ client.cancel()
+ close(client.channel)
+ }
+ }
+ lb.clientsMutex.Unlock()
+ }
}
// package level var
broadcaster = b
+// poll redis, dedup leaderboard values, push to broadcast to all clients
func (lb *LeaderboardBroadcaster) detectLeaderboardChanges() {
defer lb.wg.Done()
-
- // TODO: check this time conversion
ticker := time.NewTicker(time.Duration(config.AppConfig.Server.PollingIntervalSeconds) * time.Second)
defer ticker.Stop()
Hash: currentHash,
}
- // non blocking send
- select {
- case lb.broadcastChan <- update:
- default:
- }
+ lb.broadcastToAllClients(update)
}
case <-lb.ctx.Done():
return
c.Writer.Flush()
metrics.ActiveSSEConnections.Inc()
- config.Info("New SSE conn", map[string]any{"Num active clients": metrics.ActiveSSEConnections})
+ config.Info("New SSE conn", map[string]any{})
defer metrics.ActiveSSEConnections.Dec()
- broadcastChan := broadcaster.GetBroadcastChannel()
+ client, channel := broadcaster.AddClient()
+ defer broadcaster.RemoveClient(client)
for {
select {
- case update, ok := <-broadcastChan:
+ case update, ok := <-channel:
if !ok {
// channel closed
return
fmt.Fprintf(c.Writer, "data: %s\n\n", update.Data)
c.Writer.Flush()
metrics.SSEMessagesSent.Inc()
-
case <-c.Request.Context().Done():
metrics.DroppedSSEConnections.Inc()
config.Info("Closed SSE conn", map[string]any{"open": metrics.ActiveSSEConnections})What can be improved
- Global variable usage for leaderboardBroadcaster
- Testing - no tests yet (except for load testing benchmarks)
- Flush buffer (empty) if found filled, add in latest update (that’s required)
- Figure out how to deal with surges and spikes in traffic
- Send an initial update to client when connecting to /stream-leaderboard
Final version
As implemented in this PR.
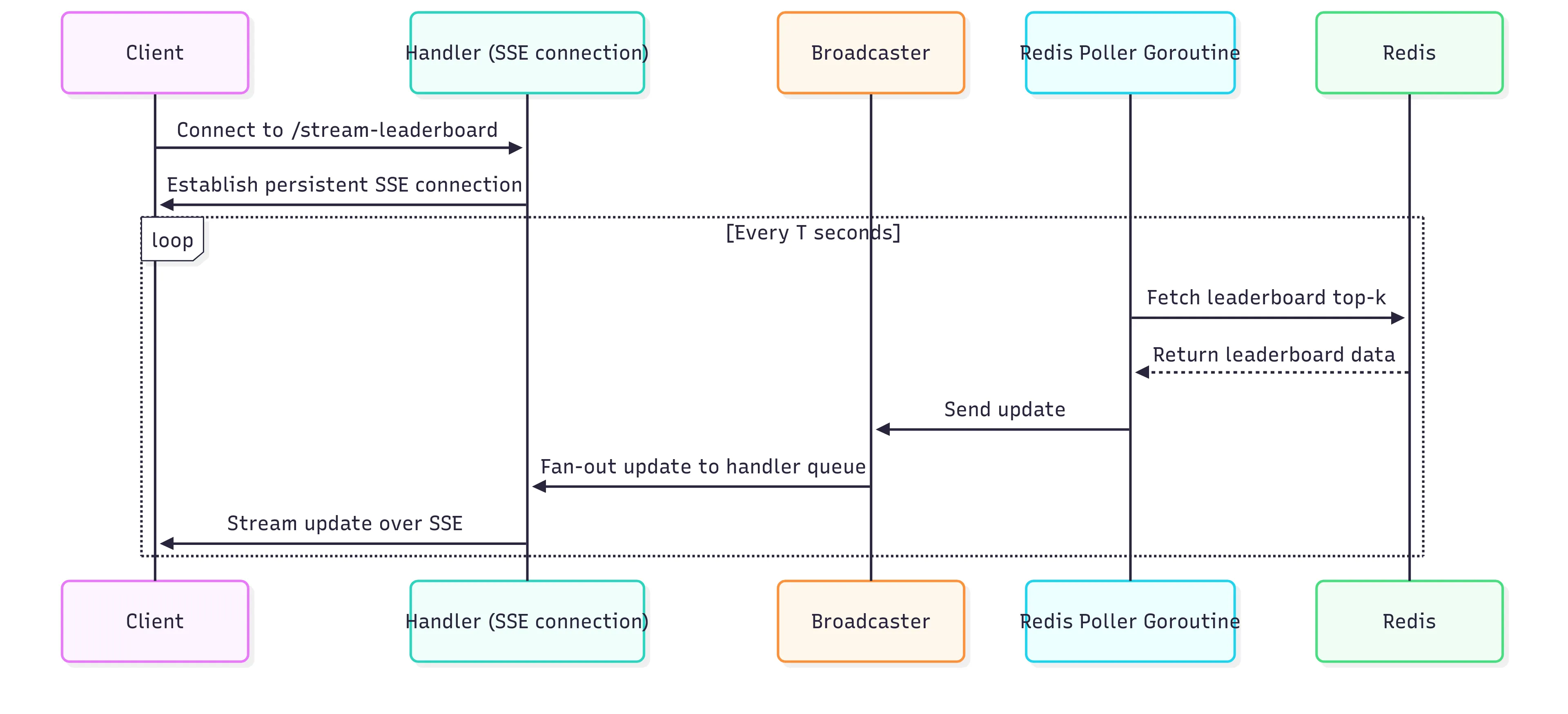
Sequence diagram of a SSE request
What improved:
- Added backpressure handling (clear buffer, add latest update - intermediates do not matter in this application)
- Used JSON marshaling before hash based dedup - strings may be different as Go’s map is unordered
- Heartbeats to detect dead clients
- Fix bugs in Redis code
- Use Dependency Injection instead of global var for leaderboardBroadcaster
- Send an update to the client as soon as it connects to the SSE endpoint
/stream-leaderboard
What can be improved
- Still need to figure out how to deal with spikes in traffic (100s of clients try to connect at once)
Learnings
- Go channels are point to point, not broadcast
- You really need to have different kinds of tests for sanity checks
- Sometimes test code can be the issue (earlier load test scripts were a bottleneck)
- Connection pools matter for external systems like Redis, databases
- Ephemeral ports can be a hidden scaling limit
- Observability is not optional
Future work
Immediate fixes
- Send a leaderboard update immediately on connecting to SSE stream
- Understand how to cleanly shut down connections
Scaling improvements
- Add retries to SSE send, add jitter to prevent thundering herd
- Learn how to deal with spikes in traffic
- Explore horizontal scaling in this kind of system
Production considerations
- Reduce Grafana and Prometheus interval
- Throughput metrics - per time interval
- Validation for score updates - with proper error messages
- Authentication for game servers
- Postgres integration (leaderboard historical data - aggregatiion)
- Redis/database based id to username translation
Implementation notes
Tech stack
I tried to choose the most sensible tech stack, and ended up with:
- Go for the backend (high concurrency, more fine grained control and less resource usage than python)
- Redis for the sorted set data structure. Could have implemented in pure Go, but overkill at this stage.
- Prometheus and Grafana for observability - wanted to learn how observability works and get hands on experience with it.
- Docker and Docker compose for coordinating everything. Wrote a blog on docker optimization for this project.
- PostgreSQL for persistent storage, historical time queries (in the works).